In diesem Beitrag wollen wir zeigen, wie einfach man einen ELK-Stack auf Kubernetes deployen kann.
Auf unserem Github Repository findet man das vorgeführte Beispiel-Deployment.
Das Beispiel enthält Yaml-Dateien die notwendig sind, einen ELK-Stack auf einem Kubernetes zu deployen, darunter Ingresses, Konfigurationen und Services.
Dieses Schema beschreibt die Basisstruktur vom ELK:
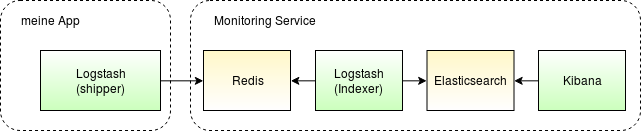
Der Logstash-shipper pushed die Daten in den Redis-cache. Der Logstash-indexer nimmt diese dann vom Redis und pushed sie in den Elasticsearch. Zuletzt können dann die Daten vom Kibana über eine WebUI visualisiert werden.
Die Elasticsearch Nodes sind untereinander über den Port 9300 verbunden und bilden einen Cluster mit sharded Daten.
Auf dem Port 9200 kann man zusätzlich Daten von etwa fluentd oder beats pushen, zudem ist die Schnittstelle des Logstash-indexers auf Port 9600 für das interne Netzwerk geöffnet, was die Kontrolle über diese ermöglicht.
Sämtliche Daten werden auf einem NFS-Share gespeichert, in unserem Fall werden die Indexes auf dem gleichem Storage mit unterschiedlichen Ordnern angelegt.
Voraussetzungen
Voraussetzung um dieses Beispiel auszuprobieren, ist ein funktionierendes Kubernetes Setup und ein NFS-Server. Hat man kein Kubernetes-Cluster zur Hand, kann man das ganze lokal mithilfe von Minikube testen.
NFS-Server
Einen NFS-Server kann man sich mit wenig Aufwand mit Vagrant bereitstellen. Ein entsprechendes Vagrantfile könnte so aussehen:
Vagrant.configure("2") do |config|
config.vm.define "nfs" do |server|
server.vm.box = "centos/7"
server.vm.hostname = "nfs.test.local"
server.vm.network :private_network, ip: "192.168.99.10"
end
end
end
Nach einem vagrant up und vagrant ssh kann man die benötigten Ordner und Einträge /etc/exports anlegen:
# mkdir /srv/es-data
# cat /etc/exports
/srv/es-data 192.168.99.0/24(rw,sync,no_root_squash)
Unser Kubernetes-Cluster befindet sich demnach im Netzwerk 192.168.99.0/24. Fehlt nur noch, den NFS-Server Dienst neuzustarten:
# systemctl restart nfs-server
Ressourcen für das Deployment
Ein ready-to-run ELK-Beispiel findet sich hier: https://github.com/afdata/elk-deployment
Für unser Beispiel muss man folgendes anpassen:
- Externe IP-Adressen in:
- elasticsearch.yaml - Zeile 18
- redis.yaml - Zeile 19
- DNS-Namen in:
- kibana.yaml - Zeile 11
- logstash.yaml - Zeile 11
- Optional kann man noch eine Reihe an Parametern in den Yaml-Dateien in configs setzen.
Hier kann man die Konfiguration unserer zwei K8s Volumes finden. Hier tragen wir dann die richtige IP-Adresse unseres NFS-Servers ein:
- name: es-data
nfs:
server: 192.168.99.10 # IP Adresse des NFS-Share auf dem die Datenbank des Elasticsearch ist.
path: "/srv/nfsshare/k8s-stage/elasticsearch"
Wichtiges vor dem Deployment
Elasticsearch Ports sind geöffnet um eine direkte Verbindung ohne
redis-logstash-indexerzu ermöglichen.Man kann daher z.B. fluentd als leichtgewichtige Alternative zum Logstash benutzen. Alle Vorteile von fluentd findet man hier
Viele fluentd Beispiele
Einstellungen für den Elasticsearch Output hier
Anzahl and Einstellungen für den Elasticserach output hier
Auf jeder Host-Maschine (Compute Node) muss ausgeführt werden:
sysctl -w vm.max_map_count=262144Abhängig von der benutzten Kubernetes Version muss man die API-Version im Yaml anpassen, bei 1.8 oder älter
batch/v2alpha1und bei neueren VersionenapiVersion: batch/v1beta1.Die API Version übeprüft man mit:
kubectl api-versionsFallsbatch/v2alpha1API fehlt:vi /etc/kubernetes/apiservermit dem Parameter--runtime-config=batch/v2alpha1=trueergänzen.Um filebeat zu starten muss man
rbac.authorization.k8s.io/v1alpha1inKUBE_API_ARGShinzufügen:
--authorization-mode=RBAC,ABAC
Neustarten von kube-apiserver und überprüfen der Version: kubectl api-versions
Ausrollen der Kubernetes Services & Ressourcen:
- Ausrollen des Namespaces:
# kubectl apply -f namespace/elasticsearch-ns.yaml
Ausrollen notwendiger Einstellungen:
# kubectl apply -f configs/.
- Ausrollen der Ingresses:
# kubectl apply -f ingress/.
- Ausrollen von Services und Pods:
# kubectl apply -f .
Folgende Topologie lässt sich damit aufbauen:
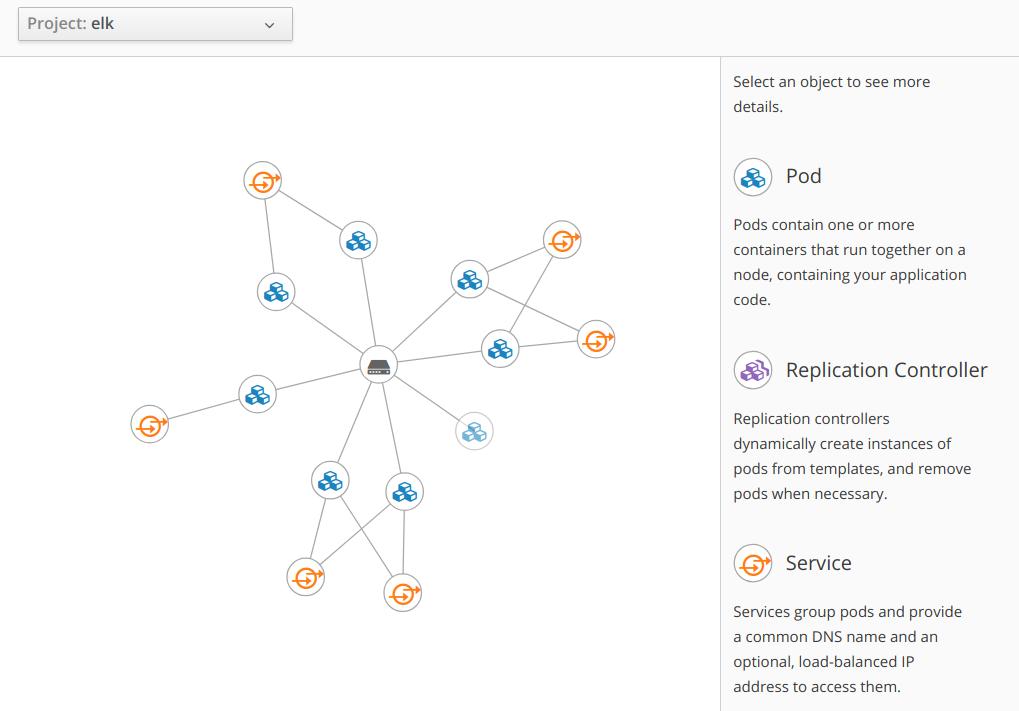
Nun können wir den Status unserer Pods auf running überprüfen:
# kubectl get pods -n elk
Das ganze sieht in etwa dann so aus:
NAME READY STATUS RESTARTS AGE
es-node-0 1/1 Running 0 1d
es-node-1 1/1 Running 0 1d
kibana-3971276974-0dtdk 1/1 Running 0 1d
kibana-3971276974-w7w08 1/1 Running 0 1d
logstash-3874044503-kkltw 1/1 Running 0 1d
logstash-3874044503-m9xfq 1/1 Running 0 1d
redis 1/1 Running 0 1d
Das Kibana Web-Interface sollte auf http://kibana.test.local erreichbar sein, genauso wie Elasticsearch auf Port 9200 für externe Verbindungen und Logstash auf 9600 für die Logstash API.
Debug
Sollte es Probleme bei dem Deployment geben, kann es sein das unser NFS-Server nicht erreichbar ist. Um unseren NFS-Server zu überprüfen, geht man wie folgt vor:
# showmount -e 192.168.99.10
output:
Export list for 192.168.99.10:
/srv/es-data 192.168.99.0/24
# mount 192.168.99.10:/srv/es-data /media && umount /media
Sollte eine Applikation nicht erreichbar sein, weil die Node IP oder der Port unbekannt ist, können die folgenden Befehle helfen:
# kubectl get service
# kubectl get nodes -o yaml
Der Befehl docker ps zeigt die laufenden Container.